Заполнение данных
Независимо от того, новичок ли вы в ClickHouse или отвечаете за существующее развертывание, пользователям неизбежно потребуется заполнить таблицы историческими данными. В некоторых случаях это относительно просто, но может стать более сложным, когда необходимо заполнить материализованные представления. Этот гид документирует некоторые процессы для этой задачи, которые пользователи могут применить к своему случаю использования.
Этот гид предполагает, что пользователи уже знакомы с концепцией Инкрементных материализованных представлений и загрузкой данных с использованием табличных функций, таких как s3 и gcs. Мы также рекомендуем пользователям прочитать наш гид по оптимизации производительности вставки из объектного хранилища, советы из которого можно применить к вставкам на протяжении всего этого гида.
Пример набора данных
На протяжении этого гида мы используем набор данных PyPI. Каждая строка в этом наборе представляет загрузку Python пакета с помощью инструмента, такого как pip.
Например, подмножество охватывает один день - 2024-12-17 и доступно публично по адресу https://datasets-documentation.s3.eu-west-3.amazonaws.com/pypi/2024-12-17/. Пользователи могут выполнять запросы с:
Полный набор данных для этого облака содержит более 320 ГБ файлов parquet. В приведенных ниже примерах мы намеренно ориентируемся на подмножества, используя шаблоны glob.
Мы предполагаем, что пользователь потребляет поток этих данных, например, из Kafka или объектного хранилища, для данных после этой даты. Схема для этих данных показана ниже:
Полный набор данных PyPI, состоящий более чем из 1 триллиона строк, доступен в нашей публичной демо-среде clickpy.clickhouse.com. Для получения дополнительной информации об этом наборе данных, включая то, как демон использует материализованные представления для повышения производительности и как данные заполняются ежедневно, смотрите здесь.
Сценарии заполнения
Заполнение данных обычно необходимо, когда поток данных потребляется с определенного момента времени. Эти данные вставляются в таблицы ClickHouse с инкрементными материализованными представлениями, которые срабатывают на блоках по мере их вставки. Эти представления могут преобразовывать данные перед вставкой или вычислять агрегаты и отправлять результаты в целевые таблицы для последующего использования в downstream-приложениях.
Мы попытаемся рассмотреть следующие сценарии:
- Заполнение данных при существующем приеме данных - Загружаются новые данные, и исторические данные необходимо заполнить. Эти исторические данные были идентифицированы.
- Добавление материализованных представлений к существующим таблицам - Новые материализованные представления нужно добавить в настройку, для которой уже были заполнены исторические данные, и данные уже транслируются.
Мы предполагаем, что данные будут заполняться из объектного хранилища. В любом случае, мы стремимся избегать пауз в вставке данных.
Мы рекомендуем заполнять исторические данные из объектного хранилища. Данные следует экспортировать в Parquet, где это возможно, для оптимальной производительности чтения и сжатия (уменьшенный сетевой трафик). Размер файла около 150MB обычно предпочтителен, но ClickHouse поддерживает более 70 форматов файлов и способен обрабатывать файлы любых размеров.
Использование дублирующих таблиц и представлений
Для всех вышеназванных сценариев мы полагаемся на концепцию "дублирующих таблиц и представлений". Эти таблицы и представления представляют собой копии тех, которые использовались для потоковых данных, и позволяют выполнять заполнение изолированно с легким средством восстановления в случае возникновения сбоя. Например, у нас есть следующая основная таблица pypi и материализованное представление, которое вычисляет количество загрузок на проект Python:
Мы наполняем основную таблицу и связанное представление подмножеством данных:
Предположим, мы хотим загрузить другое подмножество {101..200}. Хотя мы могли бы вставить непосредственно в pypi, мы можем сделать это заполнение изолированно, создав дублирующие таблицы.
Если заполнение не удалось, мы не затронули наши основные таблицы и можем просто обрезать наши дублирующие таблицы и повторить.
Чтобы создать новые копии этих представлений, мы можем использовать оператор CREATE TABLE AS с суффиксом _v2:
Мы заполняем это нашим 2-м подмножеством примерно того же размера и подтверждаем успешную загрузку.
Если на любом этапе этого второго задания возникла ошибка, мы могли бы просто обрезать наши pypi_v2 и pypi_downloads_v2 и повторить загрузку данных.
После завершения загрузки данных мы можем переместить данные из наших дублирующих таблиц в основные таблицы, используя оператор ALTER TABLE MOVE PARTITION.
Вызов MOVE PARTITION выше использует название партиции (). Это представляет единственную партию для этой таблицы (которая не имеет партиционирования). Для таблиц, которые партиционированы, пользователям нужно будет вызывать несколько MOVE PARTITION - по одному для каждой партиции. Названия текущих партиций можно установить из таблицы system.parts, например: SELECT DISTINCT partition FROM system.parts WHERE (table = 'pypi_v2').
Теперь мы можем подтвердить, что pypi и pypi_downloads содержат полные данные. pypi_downloads_v2 и pypi_v2 можно безопасно удалить.
Важно отметить, что операция MOVE PARTITION является как легковесной (используя жесткие ссылки), так и атомарной, т.е. она либо завершается успешно, либо заканчивается с ошибкой без промежуточного состояния.
Мы сильно используем этот процесс в наших сценариях заполнения ниже.
Заметьте, что этот процесс требует от пользователей выбирать размер каждой операции вставки.
Более крупные вставки, т.е. больше строк, будут означать, что потребуется меньше операций MOVE PARTITION. Однако это должно быть сбалансировано с учетом затрат в случае сбоя вставки, например, из-за прерывания сети, чтобы восстановить. Пользователи могут дополнить этот процесс пакетной загрузкой файлов, чтобы снизить риск. Это может быть выполнено как с помощью диапазонных запросов, например, WHERE timestamp BETWEEN 2024-12-17 09:00:00 AND 2024-12-17 10:00:00, или с помощью шаблонов glob. Например,
ClickPipes использует этот подход при загрузке данных из объектного хранения, автоматически создавая дубликаты целевой таблицы и ее материализованных представлений, избегая необходимости пользователю выполнять указанные выше шаги. Используя несколько рабочих потоков, каждый из которых обрабатывает разные подмножества (через шаблоны glob) и имеет свои дублирующие таблицы, данные могут быть быстро загружены с семантикой exactly-once. Для заинтересованных пользователей дополнительную информацию можно найти в этом блоге.
Сценарий 1: Заполнение данных при существующем приеме данных
В этом сценарии мы предполагаем, что данные для заполнения не находятся в изолированном облаке и, следовательно, требуется фильтрация. Данные уже вставляются, и можно идентифицировать временную метку или монотонный столбец, с которого необходимо заполнить исторические данные.
Этот процесс включает следующие шаги:
- Идентифицировать контрольную точку - либо временную метку, либо значение столбца, с которого необходимо восстановить исторические данные.
- Создать дубликаты главной таблицы и целевых таблиц для материализованных представлений.
- Создать копии любых материализованных представлений, указывающих на целевые таблицы, созданные на этапе (2).
- Вставить данные в нашу дублирующую основную таблицу, созданную на этапе (2).
- Переместить все партиции из дублирующих таблиц в их оригинальные версии. Удалить дублирующие таблицы.
Например, в наших данных PyPI мы можем идентифицировать минимальную временную метку и, таким образом, нашу "контрольную точку".
Из вышеуказанного мы знаем, что нам нужно загрузить данные до 2024-12-17 09:00:00. Используя наш ранее описанный процесс, мы создаем дублирующие таблицы и представления и загружаем подмножество, используя фильтр по временной метке.
Фильтрация по временным меткам в Parquet может быть очень эффективной. ClickHouse будет читать только столбец временной метки, чтобы определить полный диапазон данных для загрузки, минимизируя сетевой трафик. Индексы Parquet, такие как min-max, также могут быть использованы движком запросов ClickHouse.
После завершения этой вставки мы можем переместить соответствующие партиции.
Если исторические данные находятся в изолированном облаке, фильтр по времени не требуется. Если временная или монотонная колонка недоступна, изолируйте свои исторические данные.
Пользователи ClickHouse Cloud должны использовать ClickPipes для восстановления исторических резервных копий, если данные могут быть изолированы в своем собственном облаке (и фильтр не требуется). Кроме того, параллелизуя загрузку с помощью нескольких рабочих потоков, тем самым уменьшая время загрузки, ClickPipes автоматизирует указанный выше процесс - создавая дублирующие таблицы как для основной таблицы, так и для материализованных представлений.
Сценарий 2: Добавление материализованных представлений к существующим таблицам
Не редкость, что новые материализованные представления нужно добавить в настройку, для которой было заполнено значительное количество данных, и данные вставляются. Временная метка или монотонный увеличивающийся столбец, который можно использовать для идентификации точки в потоке, полезны здесь и избегают пауз в загрузке данных. В приведенных ниже примерах мы предполагаем оба случая, предпочитая подходы, которые избегают пауз в загрузке.
Мы не рекомендуем использовать команду POPULATE для заполнения материализованных представлений для чего-либо, кроме небольших наборов данных, где загрузка приостановлена. Этот оператор может пропустить строки, вставленные в его исходную таблицу, с материализованным представлением, созданным после завершения хеширования на заполнение. Более того, это заполнение выполняется по всем данным и подвержено прерываниям или ограничениям памяти для больших наборов данных.
Временная метка или монотонно увеличивающийся столбец доступны
В этом случае мы рекомендуем, чтобы новое материализованное представление включало фильтр, который ограничивает строки теми, которые больше произвольных данных в будущем. Затем материализованное представление можно заполнить с этой даты, используя исторические данные из главной таблицы. Метод заполнения зависит от размера данных и сложности связанного запроса.
Наш самый простой подход включает следующие шаги:
- Создать наше материализованное представление с фильтром, который рассматривает только строки, превышающие произвольное время в ближайшем будущем.
- Запустить запрос
INSERT INTO SELECT, который вставляет данные в целевую таблицу материализованного представления, считывая из исходной таблицы с агрегатным запросом представления.
Это можно дополнительно улучшить, чтобы нацелить подмножества данных на шаге (2) и/или использовать дублирующую целевую таблицу для материализованного представления (присоедините партиции к оригиналу после завершения вставки) для облегчения восстановления после сбоя.
Рассмотрим следующее материализованное представление, которое вычисляет самые популярные проекты по часам.
Хотя мы можем добавить целевую таблицу, прежде чем добавлять материализованное представление, мы изменяем его SELECT-часть, чтобы включить фильтр, который рассматривает только строки, превышающие произвольное время в ближайшем будущем - в этом случае мы предполагаем, что 2024-12-17 09:00:00 является ближайшим временем в будущем.
После того как это представление добавлено, мы можем заполнить все данные для материализованного представления до этой даты.
Самый простой способ сделать это - просто выполнить запрос из материализованного представления по главной таблице с фильтром, который игнорирует недавно добавленные данные, вставляя результаты в целевую таблицу нашего представления через INSERT INTO SELECT. Например, для вышеуказанного представления:
В приведенном выше примере наша целевая таблица - это SummingMergeTree. В этом случае мы можем просто использовать наш оригинальный агрегатный запрос. Для более сложных случаев, которые используют AggregatingMergeTree, пользователи будут использовать функции -State для агрегатов. Пример этого можно найти здесь.
В нашем случае это относительно легкая агрегация, которая завершается за меньше чем за 3 секунды и использует менее 600 MiB памяти. Для более сложных или долгих агрегаций пользователи могут сделать этот процесс более устойчивым, используя ранее описанный подход с дублирующей таблицей, т.е. создать теневую целевую таблицу, например pypi_downloads_per_day_v2, вставить в нее данные и затем прикрепить ее результирующие партиции к pypi_downloads_per_day.
Часто запрос материализованного представления может быть более сложным (это не удивительно, иначе пользователи бы не использовали представления!) и требовать ресурсов. В редких случаях ресурсы для запроса превышают возможности сервера. Это подчеркивает одно из преимуществ материализованных представлений ClickHouse - они являются инкрементными и не обрабатывают весь набор данных за один раз!
В этом случае у пользователей есть несколько вариантов:
- Измените свой запрос, чтобы заполнить диапазоны, например
WHERE timestamp BETWEEN 2024-12-17 08:00:00 AND 2024-12-17 09:00:00,WHERE timestamp BETWEEN 2024-12-17 07:00:00 AND 2024-12-17 08:00:00и т.д. - Используйте драйвер Null для заполнения материализованного представления. Это имитирует типичное инкрементальное заполнение материализованного представления, выполняя его запрос по блокам данных (настраиваемого размера).
(1) представляет собой самый простой подход и часто бывает достаточно. Мы не включаем примеры для краткости.
Мы рассмотрим (2) более подробно ниже.
Использование драйвера Null для заполнения материализованных представлений
Драйвер Null предоставляет движок хранения, который не сохраняет данные (рассматривайте его как /dev/null мира движков таблиц). Хотя это кажется противоречивым, материализованные представления все равно будут выполняться на данных, вставленных в этот движок таблиц. Это позволяет построить материализованные представления без сохранения оригинальных данных - избегая ввода-вывода и связанных расходов на хранение.
Важно отметить, что любые материализованные представления, прикрепленные к движку таблицы, все равно выполняются по блокам данных по мере вставки - отправляя свои результаты в целевую таблицу. Эти блоки имеют настраиваемый размер. Хотя более крупные блоки могут быть более эффективными (и быстрее обрабатываться), они потребляют больше ресурсов (в основном памяти). Использование этого движка таблицы позволяет нам постепенно строить наше материализованное представление, т.е. по одному блоку за раз, избегая необходимости держать всю агрегацию в памяти.
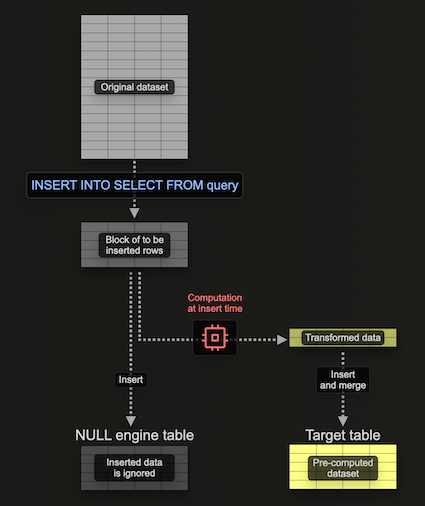
Рассмотрим следующий пример:
Здесь мы создаем таблицу Null, pypi_v2, чтобы получить строки, которые будут использоваться для построения нашего материализованного представления. Обратите внимание, как мы ограничиваем схему только необходимыми нам колонками. Наше материализованное представление выполняет агрегацию по строкам, вставленным в эту таблицу (по одному блоку за раз), отправляя результаты в нашу целевую таблицу, pypi_downloads_per_day.
Мы использовали pypi_downloads_per_day в качестве нашей целевой таблицы здесь. Для дополнительной устойчивости пользователи могут создать дублирующую таблицу, pypi_downloads_per_day_v2, и использовать ее в качестве целевой таблицы представления, как показано в предыдущих примерах. После завершения вставки партиции в pypi_downloads_per_day_v2 могут, в свою очередь, быть перемещены в pypi_downloads_per_day. Это позволит восстановиться в случае, если ваша вставка потерпела провал из-за проблем с памятью или прерываний сервера, т.е. мы просто обрезаем pypi_downloads_per_day_v2, настраиваем параметры и пробуем снова.
Чтобы заполнить это материализованное представление, мы просто вставляем соответствующие данные для заполнения в pypi_v2 из pypi.
Обратите внимание, что наше использование памяти здесь составляет 639.47 MiB.
Настройка производительности и ресурсов
Несколько факторов определят производительность и используемые ресурсы в указанном выше сценарии. Прежде чем пытаться настроить, мы рекомендуем читателям ознакомиться с механикой вставки, подробно описанной в разделе Использование потоков для чтения руководства Оптимизация производительности вставки и чтения из S3. Вкратце:
- Параллелизм чтения - Количество потоков, используемых для чтения. Контролируется через
max_threads. В ClickHouse Cloud это определяется размером экземпляра и по умолчанию равно количеству vCPU. Увеличение этого значения может улучшить производительность чтения за счет большего использования памяти. - Параллелизм вставки - Количество потоков вставки, используемых для вставки. Контролируется через
max_insert_threads. В ClickHouse Cloud это определяется размером экземпляра (от 2 до 4) и в OSS выставляется в 1. Увеличение этого значения может улучшить производительность за счет большего использования памяти. - Размер блока вставки - Данные обрабатываются в цикле, где они извлекаются, разбираются и формируются в встраиваемые блоки на основе ключа партиционирования. Эти блоки сортируются, оптимизируются, сжимаются и записываются в хранилище в виде новых частей данных. Размер вставочного блока, контролируемый настройками
min_insert_block_size_rowsиmin_insert_block_size_bytes(несжатый), влияет на использование памяти и ввод-вывод диска. Более крупные блоки используют больше памяти, но создают меньше частей, уменьшая ввод-вывод и фоновое слияние. Эти настройки представляют собой минимальные пороги (тот, который достигается первым, вызывает сброс). - Размер блока материализованного представления - Кроме вышеперечисленных механик для основной вставки, перед вставкой в материализованные представления блоки также компрессируются для более эффективной обработки. Размер этих блоков определяется настройками
min_insert_block_size_bytes_for_materialized_viewsиmin_insert_block_size_rows_for_materialized_views. Более крупные блоки позволяют более эффективную обработку за счет большего использования памяти. По умолчанию эти настройки возвращаются к значениям настроек исходной таблицыmin_insert_block_size_rowsиmin_insert_block_size_bytesсоответственно.
Для улучшения производительности пользователи могут следовать руководствам, изложенным в разделе Настройка потоков и размера блока для вставок руководства Оптимизация для вставки и чтения из S3. Обычно нет необходимости вносить изменения в min_insert_block_size_bytes_for_materialized_views и min_insert_block_size_rows_for_materialized_views, чтобы улучшить производительность. Если они были изменены, используйте те же лучшие практики, как обсуждено для min_insert_block_size_rows и min_insert_block_size_bytes.
Чтобы минимизировать использование памяти, пользователи могут поэкспериментировать с этими настройками. Это неизбежно снизит производительность. Используя ранний запрос, мы показываем примеры ниже.
Снижение max_insert_threads до 1 снижает наши накладные расходы по памяти.
Мы можем еще больше сократить использование памяти, снизив настройку max_threads до 1.
Наконец, мы можем еще больше сократить использование памяти, установив min_insert_block_size_rows в 0 (отключает его как фактор, влияющий на размер блока) и min_insert_block_size_bytes в 10485760 (10 MiB).
Наконец, имейте в виду, что снижение размеров блоков производит больше частей и вызывает большее давление на слияние. Как обсуждено здесь, эти настройки следует изменять с осторожностью.
Отсутствие временной метки или монотонно увеличивающейся колонки
Вышеупомянутые процессы зависят от наличия у пользователя временной метки или монотонно увеличивающейся колонки. В некоторых случаях это просто недоступно. В таком случае мы рекомендуем следующий процесс, который использует многие шаги, описанные ранее, но требует от пользователей приостановить прием данных.
- Приостановите вставки в вашу основную таблицу.
- Создайте дубликат вашей целевой таблицы с использованием синтаксиса
CREATE AS. - Присоедините партиции из оригинальной целевой таблицы к дубликату, используя
ALTER TABLE ATTACH. Примечание: Эта операция присоединения отличается от ранее использованного перемещения. Используя жесткие ссылки, данные в оригинальной таблице сохраняются. - Создайте новые материализованные представления.
- Перезапустите вставки. Примечание: Вставки будут обновлять только целевую таблицу, а не дубликат, который будет ссылаться только на оригинальные данные.
- Заполните материализованное представление, применив тот же процесс, что и ранее для данных с временными метками, используя дублирующую таблицу в качестве источника.
Рассмотрим следующий пример с использованием PyPI и нашим предыдущим новым материализованным представлением pypi_downloads_per_day (предположим, что мы не можем использовать временную метку):
На предпоследнем шаге мы заполняем pypi_downloads_per_day, используя наш простой подход INSERT INTO SELECT, описанный ранее. Это также можно улучшить, используя подход с таблицей Null, описанный выше, с опциональным использованием дублирующей таблицы для большей надежности.
Хотя эта операция требует приостановки вставок, промежуточные операции обычно могут быть выполнены быстро - минимизируя любые перерывы в данных.