JDBC Connector
Этот коннектор должен использоваться только в случае, если ваши данные простые и состоят из примитивных типов данных, например, int. Специфические типы ClickHouse, такие как maps, не поддерживаются.
Для наших примеров мы используем дистрибутив Confluent для Kafka Connect.
Ниже мы описываем простую установку, извлечение сообщений из одной темы Kafka и вставку строк в таблицу ClickHouse. Мы рекомендуем Confluent Cloud, который предлагает щедрый бесплатный уровень для тех, у кого нет среды Kafka.
Обратите внимание, что для JDBC Connector требуется схема (нельзя использовать простой JSON или CSV с JDBC коннектором). Хотя схема может быть закодирована в каждом сообщении, настоятельно рекомендуется использовать схему регистрации Confluenty, чтобы избежать сопутствующих затрат. Предоставленный скрипт вставки автоматически выводит схему из сообщений и вставляет ее в реестр — этот скрипт может быть повторно использован для других наборов данных. Ключи Kafka предполагаются как строки. Дополнительные детали о схемах Kafka можно найти здесь.
License
JDBC Connector распространяется по Лицензии сообщества Confluent
Steps
Gather your connection details
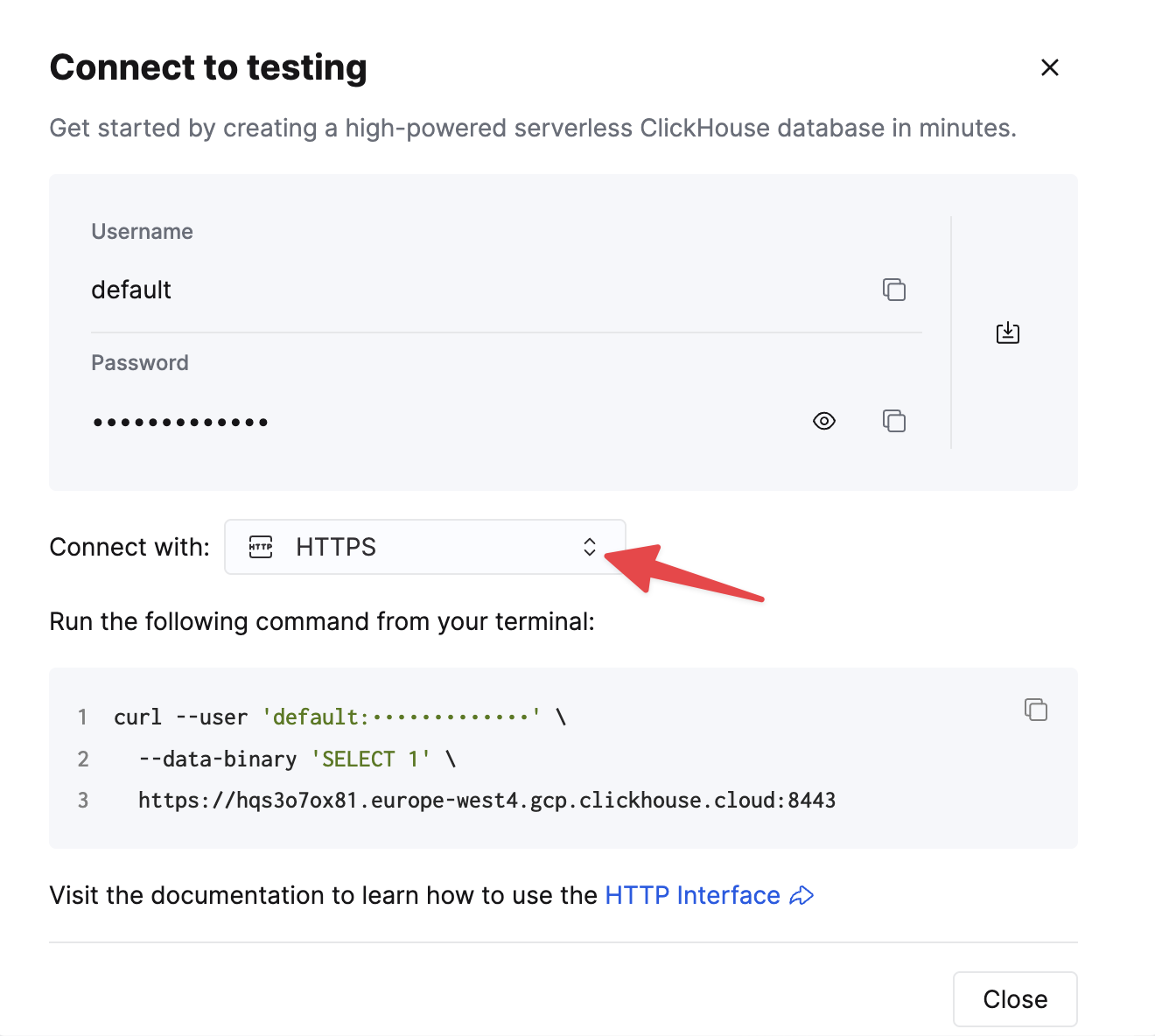
To connect to ClickHouse with HTTP(S) you need this information:
-
The HOST and PORT: typically, the port is 8443 when using TLS or 8123 when not using TLS.
-
The DATABASE NAME: out of the box, there is a database named
default, use the name of the database that you want to connect to. -
The USERNAME and PASSWORD: out of the box, the username is
default. Use the username appropriate for your use case.
The details for your ClickHouse Cloud service are available in the ClickHouse Cloud console. Select the service that you will connect to and click Connect:
Choose HTTPS, and the details are available in an example curl command.
If you are using self-managed ClickHouse, the connection details are set by your ClickHouse administrator.
1. Install Kafka Connect and Connector
Мы предполагаем, что вы скачали пакет Confluent и установили его локально. Следуйте инструкциям по установке для установки коннектора, как описано здесь.
Если вы используете метод установки confluent-hub, ваши локальные файлы конфигурации будут обновлены.
Для отправки данных в ClickHouse из Kafka мы используем компонент Sink коннектора.
2. Download and install the JDBC Driver
Скачайте и установите JDBC драйвер ClickHouse clickhouse-jdbc-<version>-shaded.jar отсюда. Установите его в Kafka Connect, следуя инструкциям здесь. Другие драйверы могут работать, но не были протестированы.
Общая проблема: документация предлагает копировать jar в share/java/kafka-connect-jdbc/. Если у вас возникли проблемы с тем, что Connect не может найти драйвер, скопируйте драйвер в share/confluent-hub-components/confluentinc-kafka-connect-jdbc/lib/. Или измените plugin.path, чтобы включить драйвер - см. ниже.
3. Prepare Configuration
Следуйте этим инструкциям для настройки Connect в зависимости от вашего типа установки, учитывая различия междуStandalone и распределенной кластером. Если вы используете Confluent Cloud, актуальна распределенная настройка.
Следующие параметры имеют отношение к использованию JDBC коннектора с ClickHouse. Полный список параметров можно найти здесь:
_connection.url_- это должно иметь видjdbc:clickhouse://<clickhouse host>:<clickhouse http port>/<target database>connection.user- пользователь с правами на запись в целевую базу данныхtable.name.format- таблица ClickHouse для вставки данных. Она должна существовать.batch.size- Количество строк, которые нужно отправить за один раз. Убедитесь, что это установлено на достаточно большое число. Согласно рекомендациям ClickHouse минимальное значение должно составлять 1000.tasks.max- Коннектор JDBC Sink поддерживает выполнение одной или нескольких задач. Это можно использовать для увеличения производительности. Вместе с размером пакета это основной способ повышения производительности.value.converter.schemas.enable- Установите в false, если используете схему регистрации, в true, если вы встраиваете свои схемы в сообщения.value.converter- Установите в зависимости от вашего типа данных, например для JSON,io.confluent.connect.json.JsonSchemaConverter.key.converter- Установите наorg.apache.kafka.connect.storage.StringConverter. Мы используем строковые ключи.pk.mode- Не актуально для ClickHouse. Установите в none.auto.create- Не поддерживается и должно быть false.auto.evolve- Мы рекомендуем установить false для этой настройки, хотя в будущем это может быть поддержано.insert.mode- Установите в "insert". Другие режимы в настоящее время не поддерживаются.key.converter- Установите в зависимости от типов ваших ключей.value.converter- Установите в зависимости от типа данных в вашей теме. Эти данные должны иметь поддерживаемую схему - форматы JSON, Avro или Protobuf.
Если вы используете наш набор данных для тестирования, убедитесь, что установлены следующие параметры:
value.converter.schemas.enable- Установите в false, так как мы используем схему регистрации. Установите в true, если вы встраиваете схему в каждое сообщение.key.converter- Установите в "org.apache.kafka.connect.storage.StringConverter". Мы используем строковые ключи.value.converter- Установите "io.confluent.connect.json.JsonSchemaConverter".value.converter.schema.registry.url- Установите на URL сервера схемы вместе с учетными данными для сервера схемы через параметрvalue.converter.schema.registry.basic.auth.user.info.
Примеры файлов конфигурации для образца данных Github можно найти здесь, предполагая, что Connect работает в режиме standalone и Kafka размещен в Confluent Cloud.
4. Create the ClickHouse table
Убедитесь, что таблица была создана, удалив ее, если она уже существует из предыдущих примеров. Пример совместимой таблицы с уменьшенным набором данных Github показан ниже. Обратите внимание на отсутствие любых типов Array или Map, которые в настоящий момент не поддерживаются:
5. Start Kafka Connect
Запустите Kafka Connect в standalone или distributed режиме.
6. Add data to Kafka
Вставьте сообщения в Kafka, используя предоставленный скрипт и конфигурацию. Вам нужно будет изменить github.config, чтобы включить ваши учетные данные Kafka. Скрипт в настоящее время настроен на использование с Confluent Cloud.
Этот скрипт можно использовать для вставки любого ndjson файла в тему Kafka. Он попытается автоматически вывести схему для вас. Предоставленная образцовая конфигурация будет только вставлять 10k сообщений - измените здесь, если это необходимо. Эта конфигурация также удаляет любые несовместимые поля Array из набора данных во время вставки в Kafka.
Это необходимо для того, чтобы JDBC коннектор преобразовывал сообщения в команды INSERT. Если вы используете свои данные, убедитесь, что вы либо вставляете схему с каждым сообщением (установив _value.converter.schemas.enable _в true), либо обеспечиваете, чтобы ваш клиент публиковал сообщения, ссылаясь на схему в реестре.
Kafka Connect должен начать потреблять сообщения и вставлять строки в ClickHouse. Обратите внимание, что предупреждения относительно "[JDBC Compliant Mode] Transaction is not supported." являются ожидаемыми и могут быть проигнорированы.
Простой запрос к целевой таблице "Github" должен подтвердить вставку данных.
Recommended Further Reading
- Параметры конфигурации Kafka Sink
- Глубокое погружение в Kafka Connect – JDBC Source Connector
- Глубокое погружение в JDBC Sink Kafka Connect: Работа с первичными ключами
- Kafka Connect в действии: JDBC Sink - для тех, кто предпочитает смотреть, а не читать.
- Глубокое погружение в Kafka Connect – Конвертеры и сериализация объяснены