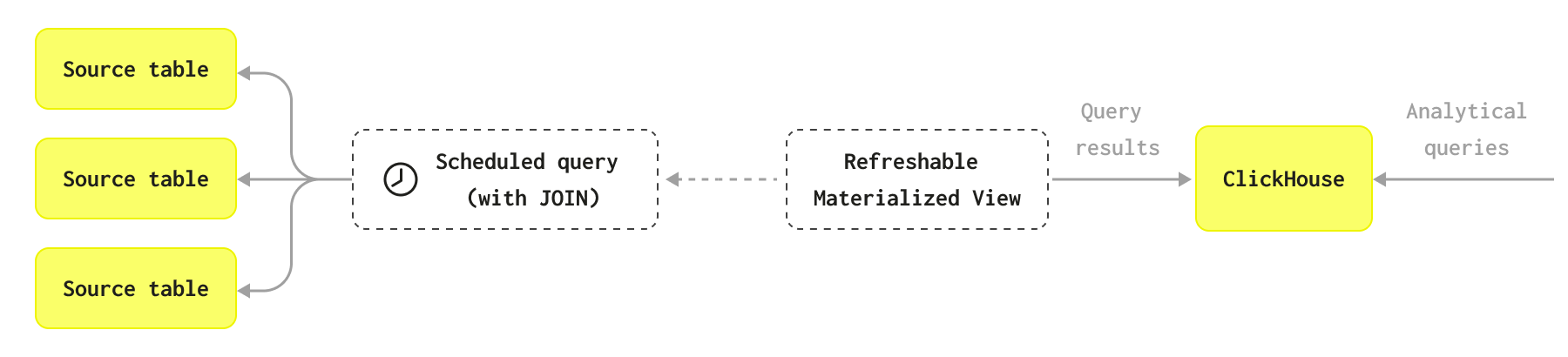
Обновляемое материализованное представление
Обновляемые материализованные представления концептуально аналогичны материализованным представлениям в традиционных OLTP базах данных, которые хранят результат определенного запроса для быстрого извлечения и снижают необходимость многократного выполнения ресурсоемких запросов. В отличие от инкрементных материализованных представлений ClickHouse, это требует периодического выполнения запроса на полном наборе данных - результаты которого хранятся в целевой таблице для выполнения запросов. Этот набор результатов, теоретически, должен быть меньше исходного набора данных, что позволяет последующему запросу выполняться быстрее.
Схема объясняет, как работают обновляемые материализованные представления:
Вы также можете посмотреть следующее видео:
Когда следует использовать обновляемые материализованные представления?
Инкрементные материализованные представления ClickHouse крайне мощные и, как правило, масштабируются намного лучше, чем подход, используемый обновляемыми материализованными представлениями, особенно в случаях, когда необходимо выполнять агрегацию по одной таблице. Путем вычисления агрегации только по каждому блоку данных по мере его вставки и объединения инкрементных состояний в финальной таблице, запрос выполняется только на подмножестве данных. Этот метод позволяет обрабатывать потенциально петабайты данных и обычно является предпочтительным методом.
Тем не менее, есть сценарии, в которых этот инкрементный процесс не требуется или не применим. Некоторые задачи либо несовместимы с инкрементным подходом, либо не требуют обновлений в реальном времени, и вместо этого более уместно периодическое восстановление. Например, вы можете захотеть регулярно выполнять полное пересчитывание представления по полному набору данных, потому что оно использует сложное соединение, что несовместимо с инкрементным подходом.
Обновляемые материализованные представления могут выполнять пакетные процессы, осуществляющие такие задачи, как денормализация. Могут быть созданы зависимости между обновляемыми материализованными представлениями так, что одно представление зависит от результатов другого и выполняется только после его завершения. Это может заменить запланированные рабочие процессы или простые DAG, такие как dbt. Чтобы узнать больше о том, как задать зависимости между обновляемыми материализованными представлениями, перейдите в раздел СОЗДАТЬ ПРЕДСТАВЛЕНИЕ,
Зависимости.
Как обновить обновляемое материализованное представление?
Обновляемые материализованные представления обновляются автоматически через интервал, который определяется во время создания. Например, следующее материализованное представление обновляется каждую минуту:
Если вы хотите принудительно обновить материализованное представление, вы можете использовать конструкцию SYSTEM REFRESH VIEW:
Вы также можете отменить, остановить или запустить представление. Для получения более подробной информации смотрите документацию по управлению обновляемыми материализованными представлениями.
Когда в последний раз обновлялось обновляемое материализованное представление?
Чтобы узнать, когда в последний раз обновлялось обновляемое материализованное представление, вы можете выполнить запрос к системной таблице system.view_refreshes, как показано ниже:
Как я могу изменить частоту обновления?
Чтобы изменить частоту обновления обновляемого материализованного представления, используйте синтаксис ALTER TABLE...MODIFY REFRESH.
После этого вы можете использовать запрос Когда в последний раз обновлялось обновляемое материализованное представление?, чтобы проверить, что частота обновления была изменена:
Использование APPEND для добавления новых строк
Функция APPEND позволяет вам добавлять новые строки в конец таблицы вместо того, чтобы заменять все представление.
Одним из применений этой функции является захват снимков значений в определенный момент времени. Например, представим, что у нас есть таблица events, заполняемая потоком сообщений из Kafka, Redpanda или другой платформы потоковых данных.
Этот набор данных содержит 4096 значений в колонке uuid. Мы можем написать следующий запрос, чтобы найти те, у кого наибольшее общее количество:
Предположим, что мы хотим захватывать количество для каждого uuid каждые 10 секунд и хранить это в новой таблице под названием events_snapshot. Схема events_snapshot будет выглядеть следующим образом:
Мы затем можем создать обновляемое материализованное представление для заполнения этой таблицы:
Затем мы можем выполнить запрос к events_snapshot, чтобы получить количество со временем для конкретного uuid:
Примеры
Теперь давайте рассмотрим, как использовать обновляемые материализованные представления с некоторыми примерами наборов данных.
Stack Overflow
Руководство по денормализации данных показывает различные техники денормализации данных с использованием набора данных Stack Overflow. Мы заполняем данные в следующие таблицы: votes, users, badges, posts и postlinks.
В том руководстве мы показали, как денормализовать набор данных postlinks в таблицу posts с помощью следующего запроса:
Затем мы показали, как однократная вставка этих данных в таблицу posts_with_links, но в производственной системе нам следует запускать эту операцию периодически.
Обе таблицы posts и postlinks могут потенциально обновляться. Поэтому вместо того, чтобы пытаться реализовать это соединение с помощью инкрементных материализованных представлений, будет достаточно просто запланировать выполнение этого запроса с установленным интервалом, например, раз в час, для хранения результатов в таблице post_with_links.
Именно здесь может помочь обновляемое материализованное представление, и мы можем создать его с помощью следующего запроса:
Представление будет выполняться немедленно и каждый час после этого, как настроено, чтобы обеспечить отражение обновлений в исходной таблице. Важно, что при повторном выполнении запроса набор результатов обновляется атомарно и прозрачно.
Синтаксис здесь идентичен синтаксису инкрементного материализованного представления, за исключением того, что мы включаем предложение REFRESH:
IMDb
В руководстве по интеграции dbt и ClickHouse мы заполнили набор данных IMDb следующими таблицами: actors, directors, genres, movie_directors, movies и roles.
Мы можем написать следующий запрос для вычисления свода для каждого актера, упорядоченного по количеству появлений в фильмах.
Результат возвращается не слишком долго, но давайте скажем, что мы хотим, чтобы он был еще быстрее и менее ресурсоемким. Предположим, что этот набор данных постоянно обновляется - постоянно выходят новые фильмы, появляются новые актеры и режиссеры.
Пришло время для обновляемого материализованного представления, поэтому сначала создадим целевую таблицу для результатов:
Теперь мы можем определить представление:
Представление будет выполняться немедленно и каждые минуты после этого, чтобы обеспечить отражение обновлений в исходной таблице. Наш предыдущий запрос на получение свода актёров становится синтаксически проще и значительно быстрее!
Предположим, что мы добавим нового актёра, "Clicky McClickHouse" в наши исходные данные, который, как оказывается, много снимался!
Менее чем через 60 секунд наша целевая таблица обновляется, чтобы отразить плодовитость актёрской деятельности Clicky: